cygwin에서 indri 실행
indri란 검색 시스템이다. 코퍼스(테스트)들을 인덱싱하고 쿼리를 넣어서 실행하면 어떤 문서가 얼마만큼 스코어를 가지는지 알 수가 있다.
indri 시스템은 다른 시스템과 마찬가지로 Linux용과 Window 버전 두개가 존재하는데, Window 버전 같은경우 설치가 쉽고 Window 유저에게는 사용이 쉬우나 쿼리를 한개 뿐이 넣을수 없다는 단점이 있다.
따라서 본 저자는 Window용 indri의 단점을 보완해주는 Linux용 indri를 설치 및 실행 해 볼 것이다.
이글은 2013년 5월 30일에 작성한다.
1.indri 설치
아래의 사이트에서 최신 버전의 indri를 다운 받자.
http://www.lemurproject.org/download-archive.php
tar 파일을 cygwin이 설치된 폴더에 복사를 하고 압축 해제를 한다.
>tar -xvf indri-5.4.tar
압축이 풀린 폴더에 들어 가서 아래와 같은 명령어를 입력한다.
>./configure
>make
2.실행
실행은 위에서 언급 한 것 처럼 두 단계로 나눈다.
첫번째, 테스트 코퍼스를 인덱싱(indexing)하고
두번째, 쿼리를 넣어서 실행을 한다.
하지만, 각 단계 마다 파라미터 파일이라고 일종의 옵션을 설정하는 파일을 만들어야 하는데 그파일의 내용은 아래와 같다
"//" 이것은 프로그래밍 언어에서 주석과 같다
인덱싱 할때(indexing.txt)
<parameters>
<corpus>
<path>Courpus</path> //코퍼스의 위치
<class>txt</class> //코퍼스 파일의 형태 ex)ppt,pdf,...
</corpus>
<index>./data/index</index> //인덱싱 파일을 만들 폴더 이름
</parameters>
그리고 쿼리는 INQUERY로 만들어야 하는데
INQUERY에 대해서 나중에 시간이 난다면 다시 정리해보겠다
우선 쿼리를 실행할 때는 아래와 같은 파라미터 파일을 만들면 된다.
쿼리를 실행할때(query.txt)
<parameters>
<index>./data/index</index>
<query>
<number>1</number> //몇번째 쿼리 인지
<text>#combine(#wsyn(0.944036 대통령과 0.873368 대통령의) #wsyn(0.981478 에봇에 0.97925 다툼이 0.956589 찔러 0.948236 짜서) #wsyn(1.0 해변의) alberto fujimori #wsyn(1.0 스캔들에서) #wsyn(1.0 신문해서 1.0 받아서도 0.75493 용서받는))</text>
</query> //INQUERY의 형태 예제
<runID>testID</runID> //아이디 입력
<trecFormat>true</trecFormat>
</parameters>
여기서 쿼리가 여러개면 <number>,<text>만 순서대로 여러개 늘어 주면 된다.
이렇게 파라미터 파일이 완성 되었다면. 아래와 같은 명령어를 입력해서 인덱싱과 쿼리를 실행하면 된다.
인덱싱
./BuildIndex ./data/indexing.txt(인덱싱 파일이 있는 경로)
그러면 indexing.txt 파라미터 파일에 적힌 <index>속성의 폴더 경로에 위 테스트 코퍼스를 인덱싱한 파일이 완성 되게 된다. 여기서 중요한건 인덱싱을 한번더하게되면 중복이 되겠때문에 다른 문서를 인덱싱 할려고한다면 인덱싱 폴더의 경로를 바꿔주던가, 같은 폴더안에 파일 들을 지워 줘야한다.
그리고 실행은
./IndriRunQuery ./data/query.txt(쿼리 파일이 있는 경로)
이렇게 하면 화면에 뿌려 지게 되는데
파일로 존재하게 하고 싶다면
./IndriRunQuery ./data/query.txt >>a.txt
라하면된다. 여기서도 마찬가지로 a.txt 한 파일의 결과 값에 쿼리를 실행 했다면 결과 값이 중복되어 쌓이게 때문에 주의 해야 한다.
수정중
2013년 5월 30일 목요일
2013년 5월 27일 월요일
[how to use the GIZA++ on Window by Cygwin] : Cygwin으로 Giza++ 사용하기
GIZA++은 번역 확률을 구하는 툴이다(SMT:statical machine translation).
IBM Model 1~5까지 사용 가능하고 HMM으로 word alignment를 할 수 있다.
기본적으로 Linux 환경에서 설치 및 사용이 가능한데,
Windows 사용자라면 Cygwin을 별로도 설치해서 사용 할 수 있다.
Cygwin은 Windows에서 Linux 처럼 사용 할 수 있는 tool이다.
저자는 BigData를 처리를 해야 하고 원래 OS가 윈도우라서 일부로 Cygwin에서 설치 및 사용 해보았다.
한국어로 설명이 잘 되어 있는 웹페이지가 없으므로 도움이 되고자 몇자 적어본다.
이 블로그는 http://arabicnlp.blogspot.kr/2009/06/how-to-setup-giza-on-windows.html를 참조 하였다.
이글은 2013년 5월 28일에 작성 되었다.
우선 GIZA++과 Cygwin에 대해서 설명이 더 필요 한다면 아래의 링크를 참조 하기 바란다.
GIZA++ : http://www.statmt.org/moses/giza/GIZA++.html
Cygwin : http://www.cygwin.com/
GIZA++ 설치
1. GIZA++을 다운로드 해라. download
2. Cygwin을 설치해라. 단, 주의 할 점은 설치시 패키지 선택창에서 다음과 같은 패키지들을 설치 해야 한다. [gcc, g++, binutils, make](cygwin을 설치 해본 사람은 알것이다. 잘 모르면 페키지 선택하는 창까지 다음다음을 눌러 보자)
3. 1번에서 받은 압축 파일을 Cygwin이 설치된 폴더(home/user/)폴더에 압축을 풀자. 그러면 폴더를 따라 들어 가면 GIZA++과 mkcls폴더가 나오는 우선 GIZA폴더로 이동해본다.
cd /giza++
make
4. 위와 같이 make 명령어를 실행 해서 설치를 한다.
5. 설치를 하면 GIZA++.exe, snt2plain.out, plain2snt.out, snt2cooc.out 가 설치 되었다고 뜰 것이다.
GIZA++ 실행
우선 parallel corpus나 comparable corpus가 있어 야된다.
parallel corpus는 source language문장이 target language 문장으로 완벽하게 번역된 문장들을 모은 말뭉치를 말하며, comparable corpus는 parallel 만큼 완벽하지만 어느정도 비슷하게 유사한 문장으로 번역된 문장들을 모은 corpus가 된다.
corpus들을 넣어주면 번역 확률이 나오는 것이다.
저자는 source를 영어, target을 한글이라 하겠다.
corpus가 준비되면 GIZA++ 폴더에 넣고 일반 text로 이루어진 파일들을 GIZA format으로 바꿔주는 작업이 필요한데 아래와 같은 명령어를 사용하면 된다.
./plain2snt.out file1(영어) file2(한글)
그러면 확장자가 vcp인 파일과 snt 파일 만들어 지게 된다.
vcp 파일은 각각 file1(영어), file2(한글)에 대해서 만들어지고
snt 파일은 file1_file2.snt, file2_file1.snt 이런식으로 파일이 만들어지는데
이것은 번역확률을 구하고잘 할때 방향(direction)을 의미 하는것 같다.(;;)
이제 GIZA를 실행하면 되는데 아래와 같다
./GIZA++ -s file1.vcp -t flie2.vcp -c file1_file2.snt -o result
저자는 영어가 source고 한글이 target이니 위와 같이 했다.
result는 최종적으로 구해지는 문서이다.
그 문서의 형태는 아래와 같다.
IBM Model 1~5까지 사용 가능하고 HMM으로 word alignment를 할 수 있다.
기본적으로 Linux 환경에서 설치 및 사용이 가능한데,
Windows 사용자라면 Cygwin을 별로도 설치해서 사용 할 수 있다.
Cygwin은 Windows에서 Linux 처럼 사용 할 수 있는 tool이다.
저자는 BigData를 처리를 해야 하고 원래 OS가 윈도우라서 일부로 Cygwin에서 설치 및 사용 해보았다.
한국어로 설명이 잘 되어 있는 웹페이지가 없으므로 도움이 되고자 몇자 적어본다.
이 블로그는 http://arabicnlp.blogspot.kr/2009/06/how-to-setup-giza-on-windows.html를 참조 하였다.
이글은 2013년 5월 28일에 작성 되었다.
우선 GIZA++과 Cygwin에 대해서 설명이 더 필요 한다면 아래의 링크를 참조 하기 바란다.
GIZA++ : http://www.statmt.org/moses/giza/GIZA++.html
Cygwin : http://www.cygwin.com/
GIZA++ 설치
1. GIZA++을 다운로드 해라. download
2. Cygwin을 설치해라. 단, 주의 할 점은 설치시 패키지 선택창에서 다음과 같은 패키지들을 설치 해야 한다. [gcc, g++, binutils, make](cygwin을 설치 해본 사람은 알것이다. 잘 모르면 페키지 선택하는 창까지 다음다음을 눌러 보자)
3. 1번에서 받은 압축 파일을 Cygwin이 설치된 폴더(home/user/)폴더에 압축을 풀자. 그러면 폴더를 따라 들어 가면 GIZA++과 mkcls폴더가 나오는 우선 GIZA폴더로 이동해본다.
cd /giza++
make
4. 위와 같이 make 명령어를 실행 해서 설치를 한다.
5. 설치를 하면 GIZA++.exe, snt2plain.out, plain2snt.out, snt2cooc.out 가 설치 되었다고 뜰 것이다.
GIZA++ 실행
우선 parallel corpus나 comparable corpus가 있어 야된다.
parallel corpus는 source language문장이 target language 문장으로 완벽하게 번역된 문장들을 모은 말뭉치를 말하며, comparable corpus는 parallel 만큼 완벽하지만 어느정도 비슷하게 유사한 문장으로 번역된 문장들을 모은 corpus가 된다.
corpus들을 넣어주면 번역 확률이 나오는 것이다.
저자는 source를 영어, target을 한글이라 하겠다.
corpus가 준비되면 GIZA++ 폴더에 넣고 일반 text로 이루어진 파일들을 GIZA format으로 바꿔주는 작업이 필요한데 아래와 같은 명령어를 사용하면 된다.
./plain2snt.out file1(영어) file2(한글)
그러면 확장자가 vcp인 파일과 snt 파일 만들어 지게 된다.
vcp 파일은 각각 file1(영어), file2(한글)에 대해서 만들어지고
snt 파일은 file1_file2.snt, file2_file1.snt 이런식으로 파일이 만들어지는데
이것은 번역확률을 구하고잘 할때 방향(direction)을 의미 하는것 같다.(;;)
이제 GIZA를 실행하면 되는데 아래와 같다
./GIZA++ -s file1.vcp -t flie2.vcp -c file1_file2.snt -o result
저자는 영어가 source고 한글이 target이니 위와 같이 했다.
result는 최종적으로 구해지는 문서이다.
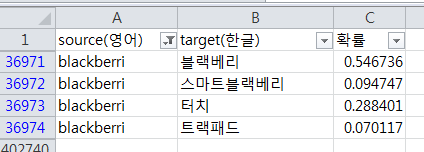
그 문서의 형태는 아래와 같다.
위 그림 A열은 source고, B열은 target이고, C 열은 source가 target으로 번역될 확률이다.
2013년 3월 14일 목요일
[Linux] 리눅스 자주 쓰는 명령어 모음
tar
tar은 은밀히 말하면 압축방식이 아니다. 일종의 묶음 파일로
이해하는 것이 좋을듯 하다. 이 tar과 gzip을 같이 사용하는 경우 tar.gz (또는 tgz)라는 확장자를 사용하게 된다.
tar이 비록 묶음 파일이라 하더라도 여기서는 압축파일의 하나로 이해하고 이를 묶고 푸는 방법에 대해 알아보도록
한다.
-
압축 생성
# tar cvf temp.tar
temp/
; temp 디렉터리를
temp.tar 이라는 파일로 묶는다.
(temp 디렉터리와 그 이하의 모든 파일 및 디렉터리)
-
압축 해제
# tar xvf
temp.tar
※ 옵션설명
-c : (create) 압축 파일을 생성한다.
-x : (extract) 압축 파일을 해제한다.
-v : 압축파일이 생성(해제)되는 과정을 보여준다.
-f : 압축파일 또는 Archive
장치를 사용한다.
※ tar
명령에서 옵션 앞에 붙는 "-" 기호는 붙여도 되고,
붙이지 않아도 된다.
※
gzip과 같이 압축된 파일의 경우 (tar.gz 또는
tgz) -z 옵션을 사용하여 한번에 처리할 수 있다.
---------------------------------------------------------------------------------
---------------------------------------------------------------------------------
2013년 2월 12일 화요일
[스터디 정리]Kappa Value
(before 간단한 용어정리)
두명의 태거들이 태깅한 코퍼스의 일치도를 구하는 것으로 태깅된 코퍼스의 신뢰도를 측정할 수 있다. 문서들의 카테고리를 분류 한다고 했을 때, 첫번째 문서를 첫번째 사람은 "정치" 카테고리로 하고 두번째 사람도 "정치" 라고 했으면 1이 된다. 두번째 문서를 첫번째 사람이 "스포츠"라 하고 두번째 사람이 "사회"라고 태깅했으면 0이된다. 이 관계를 이용해서 아래의 식으로 값을 구할 수가 있다.






결국 제곱해서 더하면 아래와 같은 값을 가지게 된다.


- annotator : 태깅하는 사람, 외국 논문에서는 이렇게 표현한다. 혹은 annotation 했다고 하면 태깅한 코퍼스라고 생각하면 된다. 전문적인 training 필요로 하기때문에 시간과 비용이 많이 든다.
- tucker : 인터넷 같은 커뮤니티 공간에 태깅할 문서를 뿌리면 사용자들이 태깅한 문서를 보낸다. annotator 보다 시간과 비용은 들지 않으나 신뢰도가 좋지 않을 것같다.
Kappa Value : Cohen's Kappa Coefficient
두명의 태거들이 태깅한 코퍼스의 일치도를 구하는 것으로 태깅된 코퍼스의 신뢰도를 측정할 수 있다. 문서들의 카테고리를 분류 한다고 했을 때, 첫번째 문서를 첫번째 사람은 "정치" 카테고리로 하고 두번째 사람도 "정치" 라고 했으면 1이 된다. 두번째 문서를 첫번째 사람이 "스포츠"라 하고 두번째 사람이 "사회"라고 태깅했으면 0이된다. 이 관계를 이용해서 아래의 식으로 값을 구할 수가 있다.
k : 구하고자 하는 카파 상관계수
Pr(a) : 전체의 문서 중에서 두명의 태거가 일치한 문서 갯수
Pr(e) : 전체의 문서 중에서 두명의 태거들이 우연히 맞춘 갯수, 무작위로 계산해서 맞춘 갯수
말로 표현하니 모호한 면이 있는데 예제로 알아 보도록 하자.
위의 그림에서 Pr(a)를 구하면 총 문서 갯수가 50(20+5+10+15)이고 두 태거들이 Yes라고 한 갯수가 20, No 라고 한 갯수가 15이므로 총문서에서 두 태거의 정답 일치율은 아래의 식과 같다.
Pr(e)는 두명의 태거가 Yes, No라고 비율의 제곱을 더해주면 된다. 아래의 식과 같다.
위의 식에서 Pr(Yes)는 아래와 같다.
또한 Pr(No)는 아래와 같다.
결국 제곱해서 더하면 아래와 같은 값을 가지게 된다.
끝으로 우리가 구하고자 하는 Kappa Value 는 다음과 같은 값을 가진다.
보통 Kappa Value가 0.8 이상이 넘을 경우에는 아주 신뢰도가 높은 코퍼스라고 판단 할 수 있다고 한다.
그렇다면 태거가 2명이상일때는 어떻게 할까?
만약에 4명의 태거가 태깅을 했다고 보자, 각각을 A,B,C,D라고 하면.
4명의 태거가 태깅한 코퍼스의 신뢰도는 (A,B), (A,C), (A,D), (B,C), (B,D), (C,D) 와 같이 모두 가능한 두쌍으로 나누고 각각의 Kappa Value를 구한 다음 평균을 계산하면 된다.
2013년 1월 27일 일요일
[IR]IR의 기본 배경 지식
정보 검색(Information Retrieval)
정보 검색(情報檢索)은 문서 내에 있는 내용, 문서 그 자체, 문서에 있는 메타데이터, 데이터베이스에서 정보를 찾는 것을 말한다. 구글, 야후, 라이브 검색(MSN 검색) 등이 가장 명백한 검색 엔진이다.
정보 검색은 흔히 데이터 검색(data retrieval)과 문서 검색(document retrieval)로 구분할 수 있다.
- 데이터 검색: 구조가 있는 데이터(structured data)의 집합에 대하여 정확한 질의어(query)를 사용하여 조건에 맞는 결과 집합을 얻어내는 것으로, 일반적인 데이터베이스에서 SQL과 같은 문법에 의해 쿼리조건에 맞는 결과를 찾아내는 것을 말한다.
- 문서 검색: 구조가 없는 데이터(unstructured data)에 대하여 자유로운 형식의 모호성있는 질의어를 사용하여 관련된 결과 목록을 얻는 것으로, 대표적인 예가 자연어질의에 대하여 관련 있는 순으로 결과 목록을 보여 주는 구글, 네이버 등의검색엔진을 들 수 있다.
이와 같이 문서 검색은 질의가 모호하고 그로 인해 검색 결과는 그 관련성에 따라 높은 것에서 낮은 순으로 제시되는 것이 일반적이라는 점에서 데이터 검색과 큰 차이가 있는데, 보통 검색엔진이라는 용어는 이러한 문서 검색을 수행하는 소프트웨어 시스템을 뜻한다.
정보 검색 요소
오늘날의 정보검색시스템은 크게 데이터집합, 색인, 랭킹, 표현, 사용자피드백이라는 다섯 가지 요소로 구성되어 있다.
- 데이터집합: 검색의 대상이 되는 데이터로서 크게 DB형 데이터와 문서형 데이터로 구분될 수 있다. DB형 데이터는 날씨, 주가, 기차시간표 등과 같이 일정한 스키마를 갖고 DB에 저장되어 있는 데이터인 반면, 문서형 데이터는 제목과 본문, 생성날짜 등으로 구성된 데이터를 말한다. 문서형데이터는 다시 정형적 문서형데이터와 비정형적 문서형데이터로 나뉘는데, 정형적 문서형데이터는 지식검색데이터나 블로그데이터와 같이 비교적 나름대로의 서식을 갖추고 있는 데이터이고, 비정형적 문서형데이터는 웹문서와 같이 상대적으로 자유로운 형식의 데이터를 의미한다.
- 색인: 색인(indexing)은 문서형데이터집합에 대하여, 각 단어별 문서리스트를 생성한 것을 의미하며, 흔히 역문서리스트(inverted list)라는 용어로도 표현된다. 한편 색인방식에 따라 데이터집합을 한꺼번에 색인하는 일괄색인(batch indexing)과 점증색인(incremental indexing)으로 구분될 수 있는데, 뉴스검색은 대표적으로 점증색인을 적용하는 분야이다. 정보검색을 위한 색인과정에서 중요한 것은 주어진 문서에서 색인어를 추출하는 과정인데, 언어적 특성과 상관없이 적용될 수 있는 n-gram 방식과, 자연언어처리의 형태소분석을 통한 방식이 존재한다.
- 랭킹: 랭킹(ranking)은 입력된 질의(query)에 대하여 가장 적합한 순으로 문서형데이터들을 나열하는 작업을 의미하며, 이를 위한 다양한 검색알고리즘들이 존재한다. 여기서 적합성(relevance)은 질의와 문서와의 유사성(similarity), 문서의 최신성(freshness), 문서 고유의 품질(quality), 그리고 사용자 검색로그를 포함한 기타 여러 정보가 적절히 혼합되어 판단될 수 있다. 구글의 페이지랭크는 질의와는 상관없이 문서 고유의 품질을 문서간의 링크관계에 따라 규정하는 대표적인 품질측정 알고리즘이라 할 수 있다.
- 표현: 검색의 결과는 구글과 같이 단순리스트형식으로 사용자에게 제시될 수도 있고, 유사한 결과들이 그룹화되어 제시될 수도 있으며, 데이터의 종류(이미지, 블로그, 웹문서)등으로 구분지어 제시될 수도 있다.
- 사용자 피드백: 사용자피드백은 검색의 품질을 개선하는 데 활용되는 것으로, 사용자가 직접 검색결과에 피드백을 주는 명시적 피드백(explicit feedback)과 사용자의 검색행위를 기록해놓은 검색로그가 대표적인 암묵적 피드백(implicit feedback)으로 구분될 수 있다. 최근에는 암묵적 피드백 정보를 활용하여 검색결과를 개선하려는 연구가 활발히 진행되고 있다.
위의 문서는 위키피디아에서 발췌한 문서이다.
정보 검색을 문서 검색과 데이터 검색으로 구분 할 수 있다고 했는데, 본 저자는 문서검색을 바탕으로 설명하도록 하겠다.
더욱이 구조한 데이터인 데이터베이스(Data Base:DB)의 데이터보다 인터넷과 웹이 발전으로 웹문서가 많아 짐에 따라 문서검색에 대한 연구가 활발 하게 이루어 졌다. 데이터베이스는 정형화된 쿼리를 만들면 원하는 정보를 100% 얻을수 있지만 웹문서 같은 경우는 형식이 너무나 많고 데이터 양도 많아서 100%로의 검색 결과를 얻기는 힘들기 때문에 최근 연구가 활발하게 이루어 지고 있다고도 볼 수 있다.
더욱이 구조한 데이터인 데이터베이스(Data Base:DB)의 데이터보다 인터넷과 웹이 발전으로 웹문서가 많아 짐에 따라 문서검색에 대한 연구가 활발 하게 이루어 졌다. 데이터베이스는 정형화된 쿼리를 만들면 원하는 정보를 100% 얻을수 있지만 웹문서 같은 경우는 형식이 너무나 많고 데이터 양도 많아서 100%로의 검색 결과를 얻기는 힘들기 때문에 최근 연구가 활발하게 이루어 지고 있다고도 볼 수 있다.
위키피디아 정보검색 검색 결과(한글)
위키피디아 정보검색 검색 결과(영어)
2013년 1월 18일 금요일
[C++]내가 정한 폴더안에 파일들 입력 받기(Windows에서)!!
내가 정한 폴더안에 있는 파일들을 입력 받아보자.


이 글은 운영체제를 Windows로 사용하고 Visual Studio 2010을 기준으로 설명하겠다.
우선 Linux에서는 제공되나 Window에서는 제공이 안되는 "dirent.h" 헤더파일을 추가하여야 한다.
개인 PC에 Visual Studio 2010이 설치된 폴더에 가면 VC폴더가 있고, VC폴더안에 include라는 폴더가 있다. 여기에 dirent.h 헤더파일을 추가 하자.
다운로드 : dirent.h
헤더 파일을 추가했다면 아래 소스파일 참고 하면된다.
*조건 : C:\\documents 라는 폴더에 파일들이 존재
30~32 줄에 보면 이상한파일(?)을 제거하기위해서 미리 파일 포인터를 이동시키는 것을 확인 할 수있는데, Linux 사용자나 DOS 환경에서 컴파일을 해본 사람이면 알수 있는데, 상위폴더로 가는 "." 혹은 ".."을 넘기기 위해서이다. 즉 우리가 원하는 파일은 3번째에 나오는것을 알수 있었다.
다른 내용은 주석을 참고하면 충분히 확인할 수 있다.
참고로 Java와 다르게 c++에서의 string(Java - String)을 이용 할 수있는 블로그가 있어서 링크를 걸어 본다. 참고 하기 바란다.
피드 구독하기:
글 (Atom)