IBM Model 1~5까지 사용 가능하고 HMM으로 word alignment를 할 수 있다.
기본적으로 Linux 환경에서 설치 및 사용이 가능한데,
Windows 사용자라면 Cygwin을 별로도 설치해서 사용 할 수 있다.
Cygwin은 Windows에서 Linux 처럼 사용 할 수 있는 tool이다.
저자는 BigData를 처리를 해야 하고 원래 OS가 윈도우라서 일부로 Cygwin에서 설치 및 사용 해보았다.
한국어로 설명이 잘 되어 있는 웹페이지가 없으므로 도움이 되고자 몇자 적어본다.
이 블로그는 http://arabicnlp.blogspot.kr/2009/06/how-to-setup-giza-on-windows.html를 참조 하였다.
이글은 2013년 5월 28일에 작성 되었다.
우선 GIZA++과 Cygwin에 대해서 설명이 더 필요 한다면 아래의 링크를 참조 하기 바란다.
GIZA++ : http://www.statmt.org/moses/giza/GIZA++.html
Cygwin : http://www.cygwin.com/
GIZA++ 설치
1. GIZA++을 다운로드 해라. download
2. Cygwin을 설치해라. 단, 주의 할 점은 설치시 패키지 선택창에서 다음과 같은 패키지들을 설치 해야 한다. [gcc, g++, binutils, make](cygwin을 설치 해본 사람은 알것이다. 잘 모르면 페키지 선택하는 창까지 다음다음을 눌러 보자)
3. 1번에서 받은 압축 파일을 Cygwin이 설치된 폴더(home/user/)폴더에 압축을 풀자. 그러면 폴더를 따라 들어 가면 GIZA++과 mkcls폴더가 나오는 우선 GIZA폴더로 이동해본다.
cd /giza++
make
4. 위와 같이 make 명령어를 실행 해서 설치를 한다.
5. 설치를 하면 GIZA++.exe, snt2plain.out, plain2snt.out, snt2cooc.out 가 설치 되었다고 뜰 것이다.
GIZA++ 실행
우선 parallel corpus나 comparable corpus가 있어 야된다.
parallel corpus는 source language문장이 target language 문장으로 완벽하게 번역된 문장들을 모은 말뭉치를 말하며, comparable corpus는 parallel 만큼 완벽하지만 어느정도 비슷하게 유사한 문장으로 번역된 문장들을 모은 corpus가 된다.
corpus들을 넣어주면 번역 확률이 나오는 것이다.
저자는 source를 영어, target을 한글이라 하겠다.
corpus가 준비되면 GIZA++ 폴더에 넣고 일반 text로 이루어진 파일들을 GIZA format으로 바꿔주는 작업이 필요한데 아래와 같은 명령어를 사용하면 된다.
./plain2snt.out file1(영어) file2(한글)
그러면 확장자가 vcp인 파일과 snt 파일 만들어 지게 된다.
vcp 파일은 각각 file1(영어), file2(한글)에 대해서 만들어지고
snt 파일은 file1_file2.snt, file2_file1.snt 이런식으로 파일이 만들어지는데
이것은 번역확률을 구하고잘 할때 방향(direction)을 의미 하는것 같다.(;;)
이제 GIZA를 실행하면 되는데 아래와 같다
./GIZA++ -s file1.vcp -t flie2.vcp -c file1_file2.snt -o result
저자는 영어가 source고 한글이 target이니 위와 같이 했다.
result는 최종적으로 구해지는 문서이다.
그 문서의 형태는 아래와 같다.
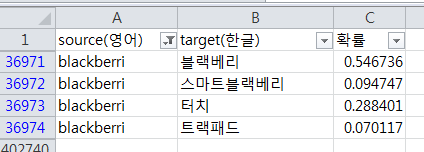
위 그림 A열은 source고, B열은 target이고, C 열은 source가 target으로 번역될 확률이다.
댓글 없음:
댓글 쓰기